um produto orientado a dados governamentais: parte 6
o nascimento do py-classifica-legal



Esse é o sétimo, e último, post de uma série de como construir um produto data-driven de ponta a ponta, caso você ainda não tenha acompanhado os demais, abaixo segue uma síntese com os respectivos links 😀.
- Em metadados de normas jurídicas federais coletamos dados do sistema LexML.
- Em um produto orientado a dados governamentais: parte 1 realizamos uma análise exploratória dos dados e definimos um recorte e um escopo para os dados do projeto.
- Em um produto orientado a dados governamentais: parte 2 realizamos a definição dos dos datasets de treino, validação e teste
- Em um produto orientado a dados governamentais: parte 3 detalhamos tudo que não deu certo no treinamento de modelos de machine learning.
- Em um produto orientado a dados governamentais: parte 4 apresentamos o treinamento de um modelo de deep learning
- Em um produto orientado a dados governamentais: parte 5 fizemos o deploy do nosso classificador de textos infraconstitucionais.
O último passo de toda prova de conceito é fazer uma apresentação das funcionalidades do projeto para os stakeholders 🕴️. Por mais que tenhamos uma api funcional, ela é o backend da nossa solução. Portanto, temos que criar uma interface de usuário para o nosso produto, isto é, o frontend da aplicação 💻. Depois de alguma pesquisa, decidimos construi-lo com o streamlit. É um framework novo, que sequer chegou a sua versão 1.0, todavia, apresenta uma capacidade incrível de produzir aplicativos webs com poucas linhas de código e ainda em python que é a linguagem que utilizamos em todo o projeto.
Antes de iniciar a construção do frontend, vamos definir uma função que será utilizada pelo backend para realizar a consulta a api.
from typing import Optional, List
import requests
import json
def parse_ementa(ementa: str) -> Optional[List[str]]:
"""
Realiza a consulta a api a partir do texto de uma ementa.
"""
url = 'https://pylegalclassifier.azurewebsites.net/predict'
payload = {"ementa" : ementa}
r = requests.post(url, json=payload)
if r.status_code == 200:
response = json.loads(r.text).get('tags')
return response
else:
return None
O streamlit como ainda não não publicou sua versão de api estável (1.0) nos indica que é um produto em maturação e evolução rápida. Portanto, algumas funcionalidades ainda estão ausentes ou mesmo em construção. Uma dessas envidências é a discussão de como o framework gerencia estados nos seus componentes. Nos faremos uso de um chunk de código disponibilizado nesse gist para alterar algumas funcionalidades da biblioteca, só recomendo o código para os mais entusiastas.
#SessionState.py
import streamlit.ReportThread as ReportThread
from streamlit.server.Server import Server
class SessionState(object):
def __init__(self, **kwargs):
"""A new SessionState object.
Parameters
----------
**kwargs : any
Default values for the session state.
Example
-------
>>> session_state = SessionState(user_name='', favorite_color='black')
>>> session_state.user_name = 'Mary'
''
>>> session_state.favorite_color
'black'
"""
for key, val in kwargs.items():
setattr(self, key, val)
def get(**kwargs):
"""Gets a SessionState object for the current session.
Creates a new object if necessary.
Parameters
----------
**kwargs : any
Default values you want to add to the session state, if we're creating a
new one.
Example
-------
>>> session_state = get(user_name='', favorite_color='black')
>>> session_state.user_name
''
>>> session_state.user_name = 'Mary'
>>> session_state.favorite_color
'black'
Since you set user_name above, next time your script runs this will be the
result:
>>> session_state = get(user_name='', favorite_color='black')
>>> session_state.user_name
'Mary'
"""
# Hack to get the session object from Streamlit.
ctx = ReportThread.get_report_ctx()
this_session = None
current_server = Server.get_current()
if hasattr(current_server, '_session_infos'):
# Streamlit < 0.56
session_infos = Server.get_current()._session_infos.values()
else:
session_infos = Server.get_current()._session_info_by_id.values()
for session_info in session_infos:
s = session_info.session
if (
# Streamlit < 0.54.0
(hasattr(s, '_main_dg') and s._main_dg == ctx.main_dg)
or
# Streamlit >= 0.54.0
(not hasattr(s, '_main_dg') and s.enqueue == ctx.enqueue)
):
this_session = s
if this_session is None:
raise RuntimeError(
"Oh noes. Couldn't get your Streamlit Session object"
'Are you doing something fancy with threads?')
# Got the session object! Now let's attach some state into it.
if not hasattr(this_session, '_custom_session_state'):
this_session._custom_session_state = SessionState(**kwargs)
return this_session._custom_session_state
O próximo passo será a construção da página para o app (app.py). Além disso, o nosso produto precisa de um nome, que após alguns segundos de reflexão 🤣 decidimos chamar 🧠 py-classifica-legal 🤖. Abaixo encontra-se, todo o código da nossa aplicação, incríveis 40 linhas de código 😲!
import streamlit as st
import SessionState
from api.response import parse_ementa
def main():
""" Classificador de normas infraconstitucionais"""
multi_tags = ['ACORDO INTERNACIONAL', 'ALTERAÇÃO', 'AMBITO', 'APROVAÇÃO',
'AREA PRIORITARIA', 'ATO', 'AUTORIZAÇÃO', 'BRASIL', 'COMPETENCIA',
'COMPOSIÇÃO', 'CONCESSÃO', 'CORRELAÇÃO', 'CREDITO SUPLEMENTAR',
'CRIAÇÃO', 'CRITERIOS', 'DECLARAÇÃO', 'DESAPROPRIAÇÃO', 'DESTINAÇÃO',
'DISPOSITIVOS', 'DOTAÇÃO ORÇAMENTARIA', 'EMPRESA DE TELECOMUNICAÇÕES',
'ESTADO DE MINAS GERAIS MG', 'ESTADO DE SÃO PAULO SP',
'ESTADO DO PARANA PR', 'ESTADO DO RIO GRANDE DO SUL RS', 'EXECUTIVO',
'EXECUÇÃO', 'FIXAÇÃO', 'FUNCIONAMENTO', 'HIPOTESE', 'IMOVEL RURAL',
'INSTITUTO NACIONAL DE COLONIZAÇÃO E REFORMA AGRARIA INCRA',
'INTERESSE SOCIAL', 'MUNICIPIO', 'NORMAS', 'OBJETIVO',
'ORÇAMENTO DA SEGURIDADE SOCIAL', 'ORÇAMENTO FISCAL',
'PAIS ESTRANGEIRO', 'RADIODIFUSÃO', 'REFORMA AGRARIA', 'REFORÇO',
'RENOVAÇÃO', 'SERVIÇO', 'TEXTO', 'UNIÃO FEDERAL', 'UTILIDADE PUBLICA']
st.title("🧠 py-classifica-legal 🤖")
st.subheader("Um classificador para normas infraconstitucionais ⚖️.")
st.markdown("O *py-classifica-legal* foi treinado com uma base de mais de 30.000 normas legais. O intuito do programa é auxiliar em uma melhor governança de dados públicos, por meio de sugestões de classificações de normas infraconstitucionais a partir de suas respectivas ementas.")
st.markdown("Você pode consultar alguns exemplos de ementas clicando <a href='http://www4.planalto.gov.br/legislacao/portal-legis/legislacao-1/decretos1/2020-decretos' target='_blank' style='color: #f97b6f;'> aqui.</a>", unsafe_allow_html=True)
session_state = SessionState.get(name="", button_sent=False)
input_ementa = st.text_area("Insira o texto da ementa", "Digite aqui.")
button_sent = st.button("Classificar")
if button_sent:
session_state.button_sent = True
if session_state.button_sent:
get_tags = parse_ementa(input_ementa)
if get_tags:
st.multiselect('Tags', multi_tags, default=get_tags)
else:
st.multiselect('Tags', multi_tags)
st.warning("Não há sugestão de classificação para a ementa consultada.")
st.markdown("<center><blockquote cite='https://netoferraz.github.io/o-eu-analitico/'><p style='color: #bfc5d3;'><i>py-classifica-legal é uma prova de conceito desenvolvida por <a href='https://netoferraz.github.io/o-eu-analitico/' target='_blank' style='color: #f97b6f;'> José Ferraz Neto</a>.</i></p></blockquote></center>", unsafe_allow_html=True)
if __name__ == "__main__":
main()
Assim, podemos iniciar o servidor do streamlit e verificar a nossa aplicação.

Com o servidor iniciado, podemos consultar a aplicação rodando localmente em http://localhost:8501. E assim, o py-classifica-legal ganha vida com uma interface simples e direita ao que se propõe. Como estamos em um estágio de prova de conceito, a velocidade da entrega é algo relevante, portanto, só queremos validar a ideia com os patrocionadores do projeto. Assim, qualquer melhoria deve ser realizada a posteriori.
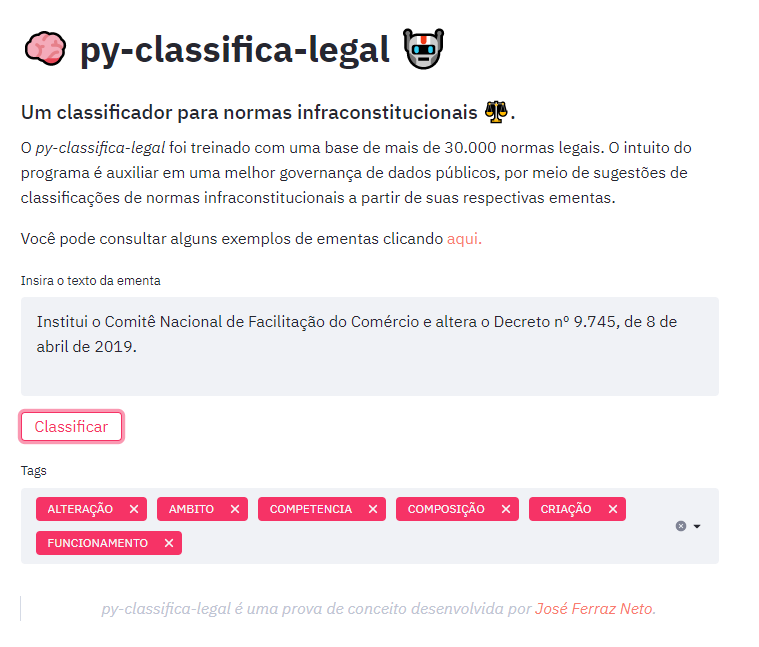
Abaixo, podemos ver o resultado de consulta de uma ementa no app.
Por fim, precisamos realizar o deploy da aplicação. Para essa etapa, decidimos utilizar a plataform do heroku. Começaremos definindo as dependências do projeto por meio do arquivo requirements.txt
Em seguida vamos construir um arquivo com algumas variáveis de configuração do projeto setup.sh.
Por fim, defineremos um arquivo Procfile que é utilizado pela plataforma do heroku.
Em termos de arquivos de configuração, finalizamos. Agora temos que criar um app no heroku e realizar o deploy. O primeiro passo é, é fazer o login pelo heroku-cli, pelo comando a seguir:
heroku login
Realizado a devida autenticação, iremos criar o app pelo comando:
heroku create py-classifica-legal
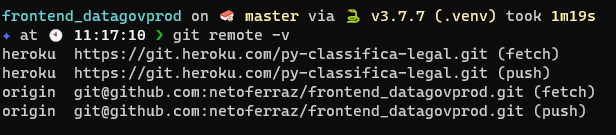
É válido ressaltar, que o diretório do projeto deve estar sob versionsamento, por exemplo, git. Uma vez criado o app pelo heroku-cli ele adicionará um remote ao seu repositório local, como apresentado abaixo.
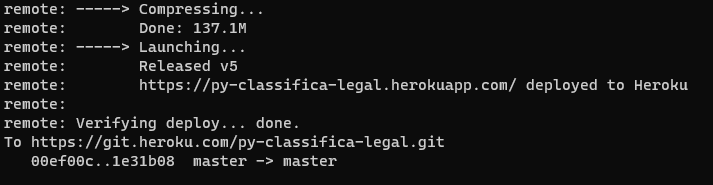
Estando todos os arquivos devidamente comitados, basta realizar o push para o heroku pelo comando:
git push heroku master
O processo de push iniciará automaticamente um build e havendo sucesso você receberá uma confirmação de deploy concluído e a url para acessar o app 🥳🥳🥳.
Finalmente, chegamos ao final do nosso projeto!! Foi uma incrível jornada que realizamos em cerca de 1 mês. Agradeço a todos que acompanharam até aqui e em breve espero ter novos projetos para desenvolvermos juntos. Até a próxima 🤓 !!
NOTA 17/02/2021: O aplicativo apresentado nessa sequência de postagens não encontra-se mais online. Caso tenham interesse em acessar ao modelo, ele está disponível nesse repositório para ser realizado o deploy local.