um produto orientado a dados governamentais: parte 5
fastapi, docker, cloud e tudo o mais para o deploy.



Esse é o sexto post de uma série de como construir um produto data-driven de ponta a ponta, caso você ainda não tenha acompanhado os demais, abaixo segue uma síntese com os respectivos links 😀.
- Em metadados de normas jurídicas federais coletamos dados do sistema LexML.
- Em um produto orientado a dados governamentais: parte 1 realizamos uma análise exploratória dos dados e definimos um recorte e um escopo para os dados do projeto.
- Em um produto orientado a dados governamentais: parte 2 realizamos a definição dos dos datasets de treino, validação e teste
- Em um produto orientado a dados governamentais: parte 3 detalhamos tudo que não deu certo no treinamento de modelos de machine learning.
- Em um produto orientado a dados governamentais: parte 4 apresentamos o treinamento de um modelo de deep learning
Dando continuidade ao nosso projeto, chegamos na etapa de deploy do modelo treinado. Os artefatos necessários para colocar em produção o nosso modelo são os seguintes arquivos:
- O encoder multilabel utilizado no treinamento: MultiLabelBinarizer
- Os dados do modelo e vocabulário do sentencepiece (spm.model e spm.vocab)
- O modelo de classificação treinado (trained_model_fp32_fwd_classifier.pkl)
É importante ressaltar que o nosso treinamento foi realizado com GPU fazendo uso de half-precision (fp16) e a máquina que iremos realizar o deploy não será alocado GPU, portanto, a inferência será realizada com CPU. Assim, foi necessário converter o modelo para fp32, o que fez o tamanho do nosso modelo dobrar de tamanho (176M).
Dito isso, criamos um repositório no github para a api do nosso projeto. A próxima etapa é definir em qual framework será construída a api e depois de avaliar algumas das opções disponíveis foi decidido fazer uso da fastapi, que é um projeto muito parecido com flask só que incorpora vários benefícios do uso de type annotation.
A estrutura inicial do backend está definida abaixo:
.
|____processor
| |____encoder.py
| |____sp.py
|____.gitignore
|____main.py
|____inference
| |____predict.py
|____LICENSE
|____README.md
|____models
| |____model.py
| |____download.py
|____artifacts
|____requirements.txt
|____.envVamos definir as dependências do projeto no requirements.txt
fastai==1.0.61
fastapi==0.60.1
uvicorn==0.11.8
sentencepiece==0.1.91
scikit-learn==0.22.2
numpy==1.19.1
python-dotenv==0.14.0
gdown==3.12.0Em seguida, iremos definir algumas variáveis de ambiente para o projeto (.env)
artifactsPath=./artifacts/
modelFileName=trained_model_fp32_fwd_classifier.pkl
mlbinarizerFileName=onehot.pkl
spmodelFileName=spm.model
spmodelVocabFileName=spm.vocabO ambiente computacional (colab) utilizado para o treinamento do nosso classificador não será o mesmo do deploy. Portanto, na instância do objeto Learner precisamos alterar o path do modelo e do vocabulário do Sentence Piece Processor. Portanto, vamos escrever um código para realizar essa modificação (./processor/sp.py)
from fastai.text import SPProcessor
from fastai.basic_train import Learner
from pathlib import Path
def _fix_sp_processor(
learner: Learner, sp_path: Path, sp_model: str, sp_vocab: str
) -> None:
"""
Fixes SentencePiece paths serialized into the model.
Parameters
----------
learner
Learner object
sp_path
path to the directory containing the SentencePiece model and vocabulary files.
sp_model
SentencePiece model filename.
sp_vocab
SentencePiece vocabulary filename.
"""
for processor in learner.data.processor:
if isinstance(processor, SPProcessor):
processor.sp_model = sp_path / sp_model
processor.sp_vocab = sp_path / sp_vocab
Precisamos também definir um código para carregar a instância do MultiLabelBinarizer usada no treinamento do modelo (./processor/encoder.py).
from dotenv import load_dotenv
from pathlib import Path
import os
import pickle
import warnings
warnings.filterwarnings("ignore") # "error", "ignore", "always", "default", "module"
load_dotenv()
artifactsPath = Path(os.getenv("artifactsPath"))
mlBinarizerFileName = os.getenv("mlbinarizerFileName")
with open(artifactsPath / mlBinarizerFileName, "rb") as f:
onehot = pickle.load(f)
Tomamos a decisão de não subir para o repositório os artefatos, principalmente, o classificador já que esse excedia os limites de tamanho permitidos pelo serviço gratuito. Portanto, foi necessário escrever uma rotina para baixá-los (./models/download.py).
import gdown
import os
artifactsPath = './artifacts'
if not os.path.exists(artifactsPath):
os.makedirs(artifactsPath)
# one hot encoder
if not os.path.isfile("./artifacts/onehot.pkl"):
gdown.download("https://drive.google.com/uc?id=1-1K0jcHICzjgcaY64UeLC_PuEN5tI_Xa")
os.rename("./onehot.pkl", "./artifacts/onehot.pkl")
# spm model
if not os.path.isfile("./artifacts/spm.model"):
gdown.download("https://drive.google.com/uc?id=1CyT0AI_PdWDZrnful6jBXFqAOfTrIOSe")
os.rename("./spm.model", "./artifacts/spm.model")
# spm vocab
if not os.path.isfile("./artifacts/spm.vocab"):
gdown.download("https://drive.google.com/uc?id=1bGetu3Uzq06OrtdvVmRfiY6uorVSayIS")
os.rename("./spm.vocab", "./artifacts/spm.vocab")
# trained_model_fp32_fwd_classifier
if not os.path.isfile("./artifacts/trained_model_fp32_fwd_classifier.pkl"):
gdown.download("https://drive.google.com/uc?id=1R6Mm_K2ARMjNEuTikMmpHO0goggh0Rg9")
os.rename(
"./trained_model_fp32_fwd_classifier.pkl",
"./artifacts/trained_model_fp32_fwd_classifier.pkl",
)
O próximo passo é instanciar o nosso modelo e atualizar o path do Processor (./models/model.py).
from processor.sp import _fix_sp_processor
from fastai.text import load_learner
from dotenv import load_dotenv
import os
from pathlib import Path
import gdown
import os
load_dotenv()
artifactsPath = Path(os.getenv("artifactsPath"))
modelFileName = os.getenv("modelFileName")
spModel = os.getenv("spmodelFileName")
spVocab = os.getenv("spmodelVocabFileName")
model = load_learner(artifactsPath, modelFileName)
_fix_sp_processor(model, artifactsPath, spModel, spVocab)
Por fim, podemos escrever a rota para consulta ao modelo (./main.py).
from inference.predict import predict
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Tuple
app = FastAPI()
class Ementa(BaseModel):
ementa: str
class Tags(BaseModel):
tags: Tuple[str, ...]
@app.post("/predict", response_model=Tags, status_code=200)
def get_prediction(Ementa: Ementa):
ementa = Ementa.ementa
predictions = predict(ementa)
if not predictions:
raise HTTPException(
status_code=404, detail="Não foi possível encontrar nenhuma tag apropriada."
)
if predictions:
return {"tags": predictions}
Vamos iniciar a aplicação.
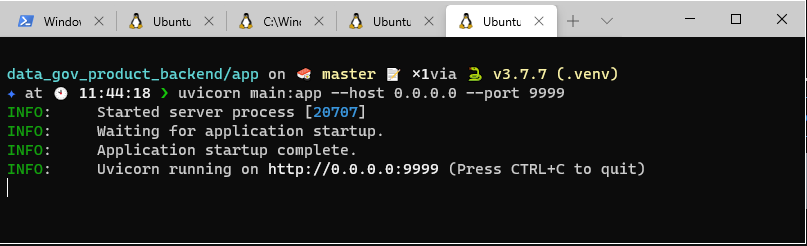
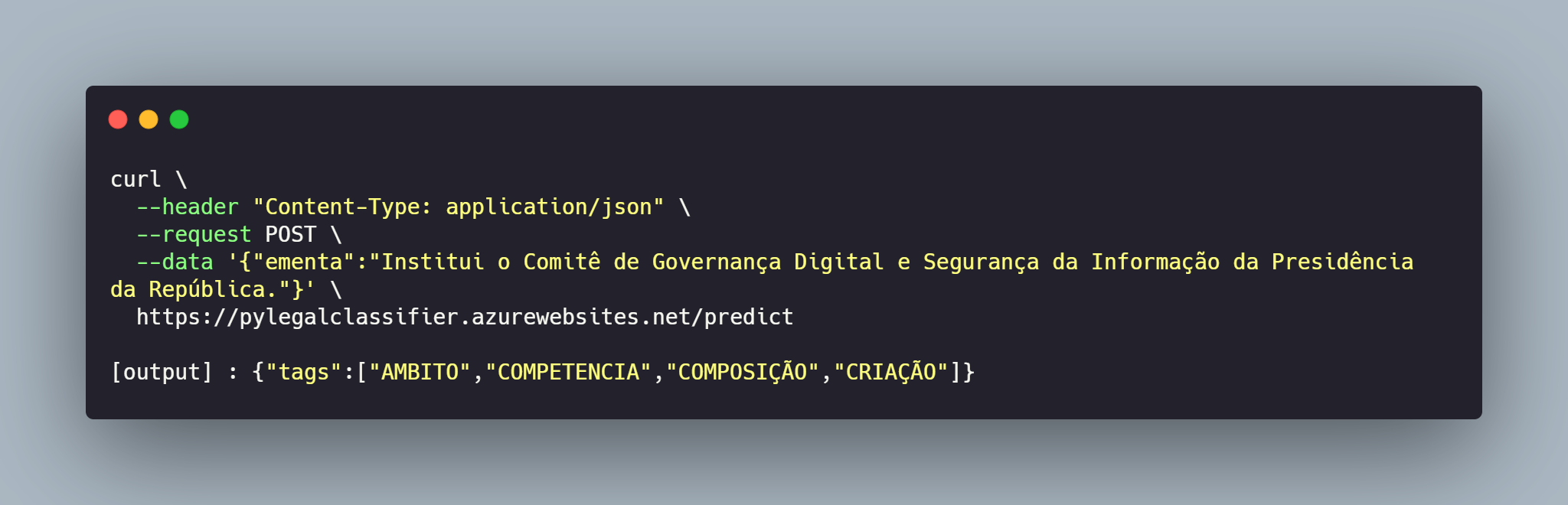
Em seguida, vamos utilizar o curl para testar uma requisição e observar o retorno da api.
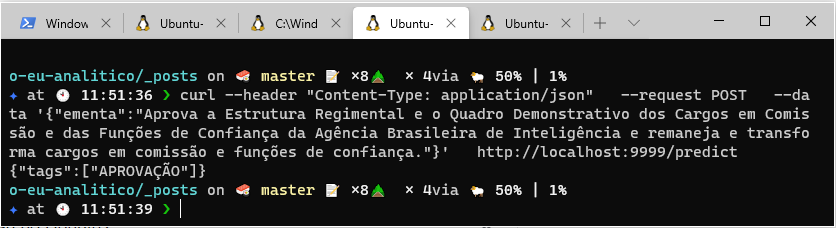
Excelente 🥳! Temos o nosso modelo respondendo por meio da chamada de uma api. O próximo passo é dockerizar a aplicação e subir o serviço para produção 🏭.
Primeiramente, vamos reorganizar a nossa estrutura de diretórios do projeto e criar um Dockerfile.
.
|____app
| |____processor
| | |____encoder.py
| | |____sp.py
| |____.gitignore
| |____main.py
| |____inference
| | |____predict.py
| |____LICENSE
| |____README.md
| |____models
| | |____model.py
| | |____download.py
| |____artifacts
| |____requirements.txt
| |____.env
|____DockerfileA estrutura do Dockerfile está detalhada abaixo.
FROM python:3.7
EXPOSE 8081
COPY ./app /app
WORKDIR /app
RUN pip install -r requirements.txt
RUN python ./models/download.py
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8081"]
Iremos realizar o deploy da nossa api utilizando a Azure. O primeiro passo é fazer o registro de uma imagem docker (docker registry).
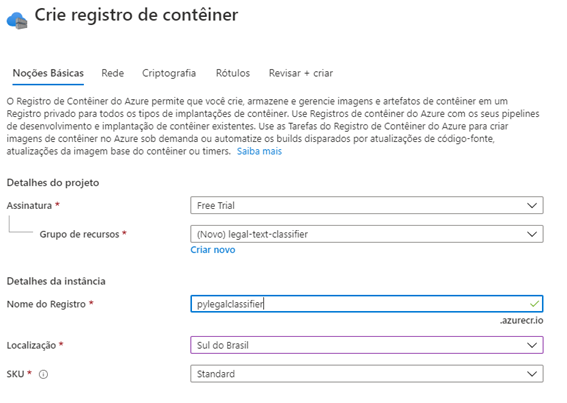
A próxima etapa é fazer o build da imagem docker.
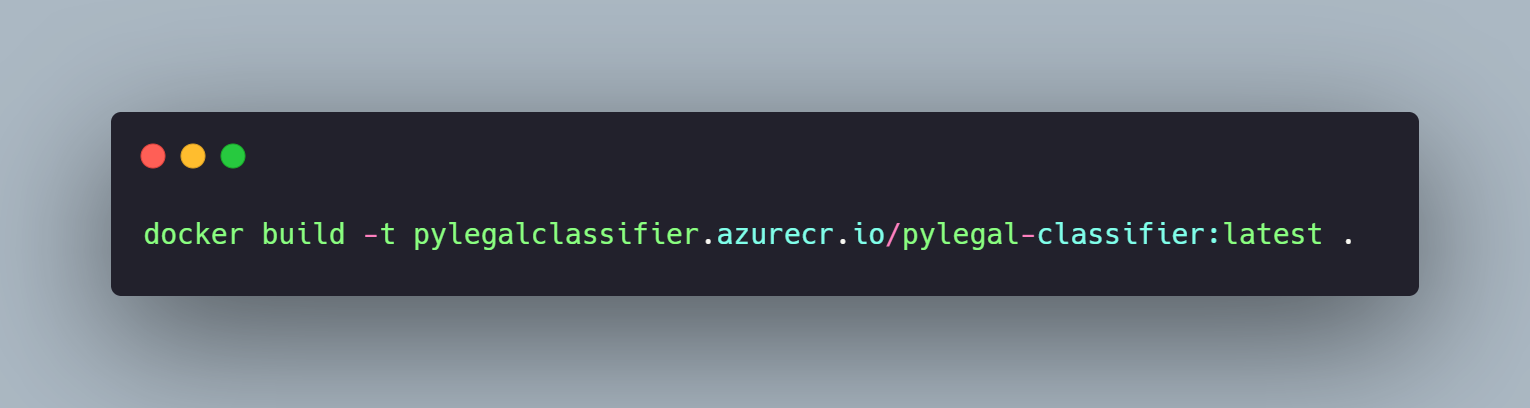
Para garantir que a aplicação está funcionando adequadamente, vamos executá-la localmente.
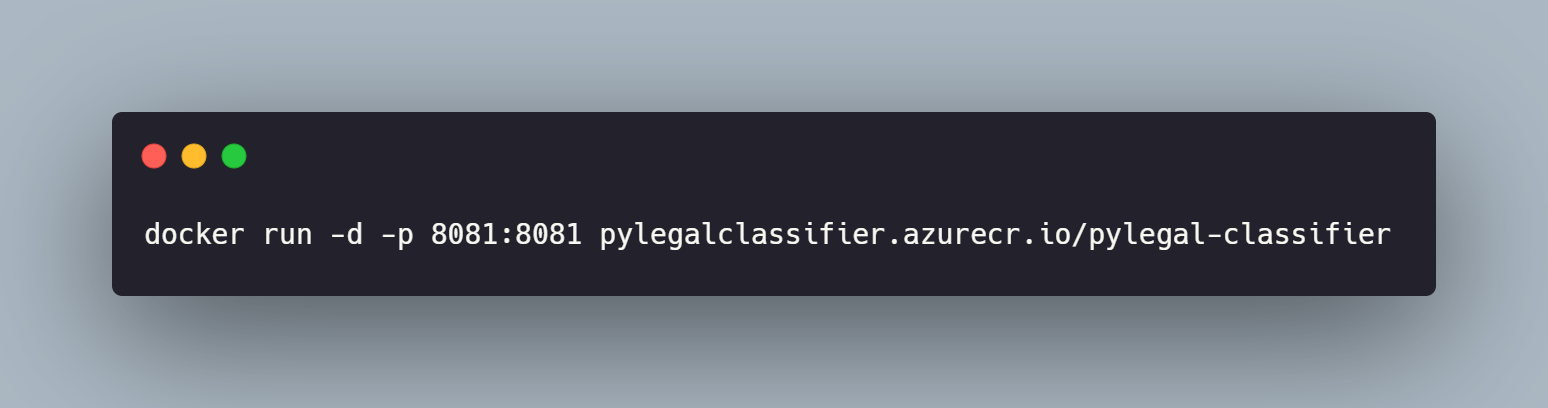
Da mesma forma realizada anteriormente, vamos realizar um post pelo curl e testar a api.

Obtivemos a confirmação de funcionamento da api no ambiente docker. Agora, podemos fazer o push da imagem para a azure. A primeira etapa é realizar a autenticação no serviço, pelo seguinte comando:
docker login pylegalclassifier.azurecr.io
Será aberto um prompt solicitando login e senha que pode ser encontrado no painel de administração da aplicação. Finalizado a autenticação, vamos fazer o push da imagem.
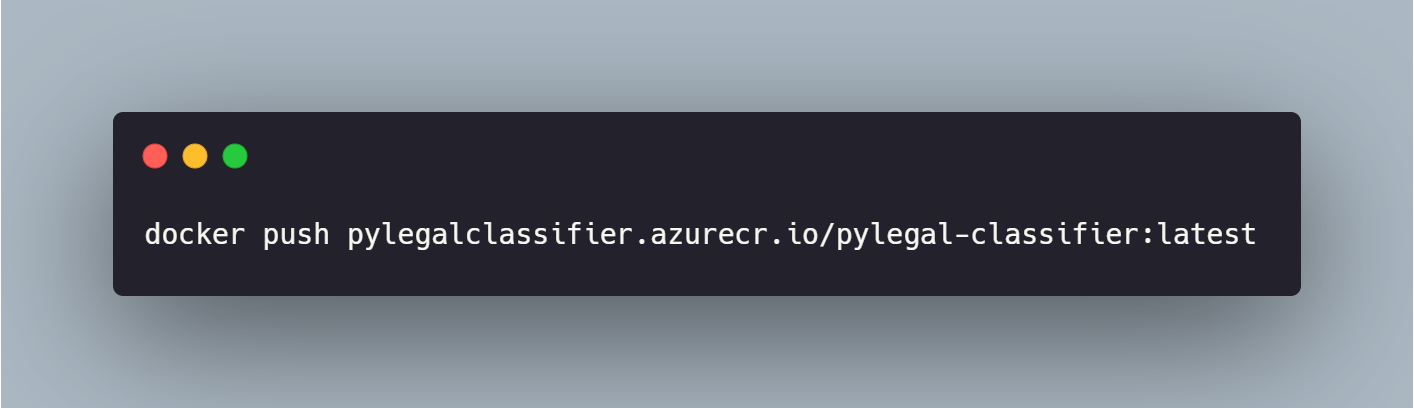
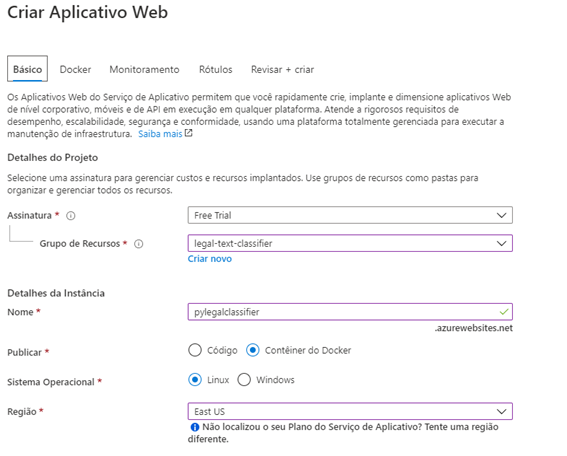
A próxima etapa é a criação de um WebApp no portal da Azure. Primeiramente, definimos o grupo de recursos o qual esse app fará parte, em seguida definimos um nome para instância, bem como definimos que nossa aplicação é baseada em um container docker, e por último definimos a região onde será alocado o recurso.
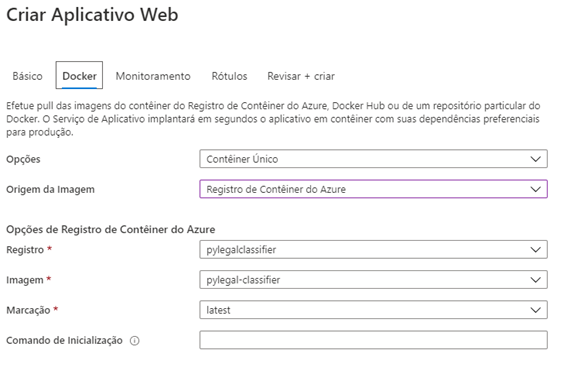
Para finalizar, na aba Docker selecionamos a imagem que registramos no docker registry.
Após confirmar todas informações, será iniciado o deploy da nossa aplicação e após alguns minutos nossa api está em produção 🚀🚀!!!
O framework fastapi cria automaticamente uma documentação para suas apis, caso queiram visualizar esse recurso basta acessar https://pylegalclassifier.azurewebsites.net/docs.
O nosso deploy 🖥️ está concluído! Estamos nos aproximando do final dessa série de postagens. Espero que vocês estejam aproveitando tanto quanto eu 🙋♂️ Assim, no próximo post iremos construir um exemplo de aplicação que pode fazer uso da nossa api. Até mais 🤘!!