lifelogging, um estilo de vida.
um registro do início da minha jornada pela ciência de dados...
Você conhece o termo lifelogging? Também conhecido por Quantified self, esse consiste em um movimento criado no início de 2007 por Gary Wolf e Kevin Kelly, editores da revista Wired, o qual promove a incorporação de tecnologia para aquisição de dados no cotidiano das pessoas.
Em tempos onde há uma explosão de gadgets1 que monitoram em tempo real desde qualidade de sono a indicadores bioquímicos do corpo humano, constrói-se campo fértil para produção de insights a partir dos dados coletados, sem mencionar todo o mercado que está se construindo em torno de wearable techonology, como apresenta um recente artigo da revista Forbes que destaca uma previsão para 2019 que sejam vendidos 85 milhões de smartwatches.

Nos últimos anos muito tem falado sobre a implementação de uma cultura data-driven nas organizações, o qual se cria um ecossistema profisisonal orientado por dados, além disso, com todos os recursos tecnológicos disponíveis atualmente, também é possível trazer para a sua vida pessoal benefícios atrelados a prática da coleta de dados pessoais.
Um blog chamado o eu analíticonão poderia começar sua trajetória de forma diferente, se não, apresentando os dados e fatos de uma vida de lifelogging. Diante das inúmeras possibilidades do que coletar sobre o nosso cotidiano, aqui vai uma sugestão:
Colete dados sobre algo que tenha importância para você e que esteja envolvido com algum aspecto de sua vida que você avalie que necessita ser aprimorado. Do contrário, todo e qualquer benefício possível do processo de coleta perderá, rapidamente, o propósito.
Esse post tem por propósito compartilhar a minha trajetória dos últimos 3 anos relacionada ao time tracking.
1. prelúdio
Em 2014 minha primeira filha nasceu e tudo mudou, e com isso passei por algo muito similar ao relatado por Josh Kaufman na excelente TED Talk The first 20 hours. Em uma nova vida de paternidade e responsabilidades, o meu tempo era mais escasso e como eu poderia me adaptar? Naquele ano começava a me chamar atenção uma nova área que estava começando a emergir chamada data science. Além disso, em 2015 eu e minha família nos mudamos mais uma vez, dessa vez para Brasília, e novamente, a vida demorou a ser organizar. Dito isso, foram necessários 2 anos para eu começar a vislumbrar que a tecnologia poderia me auxiliar na minha gestão de tempo e assim conciliar tudo que era importante para mim.
2. o início
Estamos em 2016, eu estava há quase 1 ano morando em uma nova cidade, bem como em um novo emprego. Além disso, o interesse por data science só aumentava, mas eu ainda sentia que os estudos estavam demorando a engrenar, diante de uma rotina de trabalho integral, além da atenção necessária a família, eu julgava que me faltava tempo.

Em agosto daquele ano a Udacity abriu o seu escritório em São Paulo e começou a ofertar seus cursos precificados em Real, diante disso tomei a decisão de me inscrever no Nanodegree Data Analyst e essa decisão representa o meu tipping point para uma vida data-driven. Após uma pesquisa sobre gerenciamento de tempo, descobri algumas opções de softwares para time tracking, foi quando decidi adotar o toggl, uma solução mutiplataforma para gerenciamento de tempo. Além da gestão, essa ferramenta me auxiliou na construção de um novo hábito que deveria ser incorporado a minha rotina para que pudesse ser bem sucedido no nanodegree.
Finalmente, podemos dar um salto temporal para o presente e analisar os meus dados coletados pelo toggl e as implicações disso para a minha vida data-driven.

3. lifelogging
O toggl permite, facilmente, a exportação de todo o registro para algum formato tabular, por exemplo, csv. Apesar do software fornecer várias visualizações prontas, bem como relatórios, a possibilidade de exportar o dado permite ao usuário extrapolar as funcionalidades do app.
Portanto, bastou carregar os dados no pandas para eu começar o processo de análise exploratória dos dados (EDA). Para um primeiro overview de uma série temporal registrando tempos dedicados a determinadas atividades, a visualização abaixo nos ajuda a ver o big picture desse conjunto de dados.
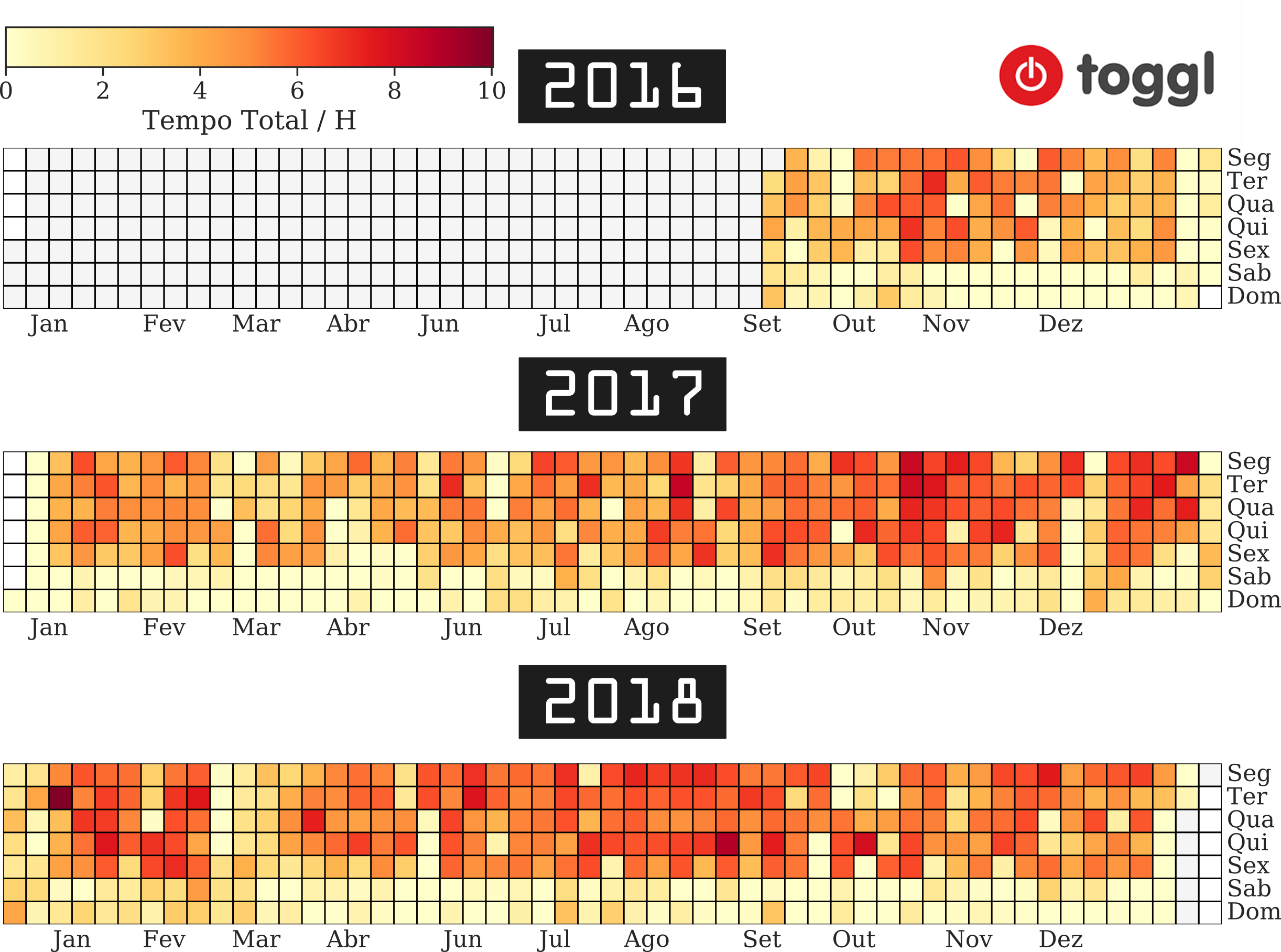
Para produção dos calendar heatmap fiz uso da biblioteca calmap que possui uma API bem simples e possui uma boa integração com os dataframes do pandas.
Pela escala de cores é possível identificar que o pico de registro é de no máximo umas 10 horas diárias e que em 2016 foi um período de incorporação do uso do aplicativo na minha rotina e que fica evidente que nos anos de 2017 e 2018 o hábito do time tracking já estava incorporado em minha vida. Além disso, essa visualização permite confirmar algo que sempre me propus: os finais de semana são períodos de descanso e dedicados a família.

Mapas de calor são eficientes para identificar trends, todavia, não são apropriados para extrair valores pontuais. Para tanto, o uso de um gráfico de barras atende melhor a esse propósito. Assim, pode-se constatar que os dias de início da semana são aqueles onde há um maior engajamento de lifelogging.
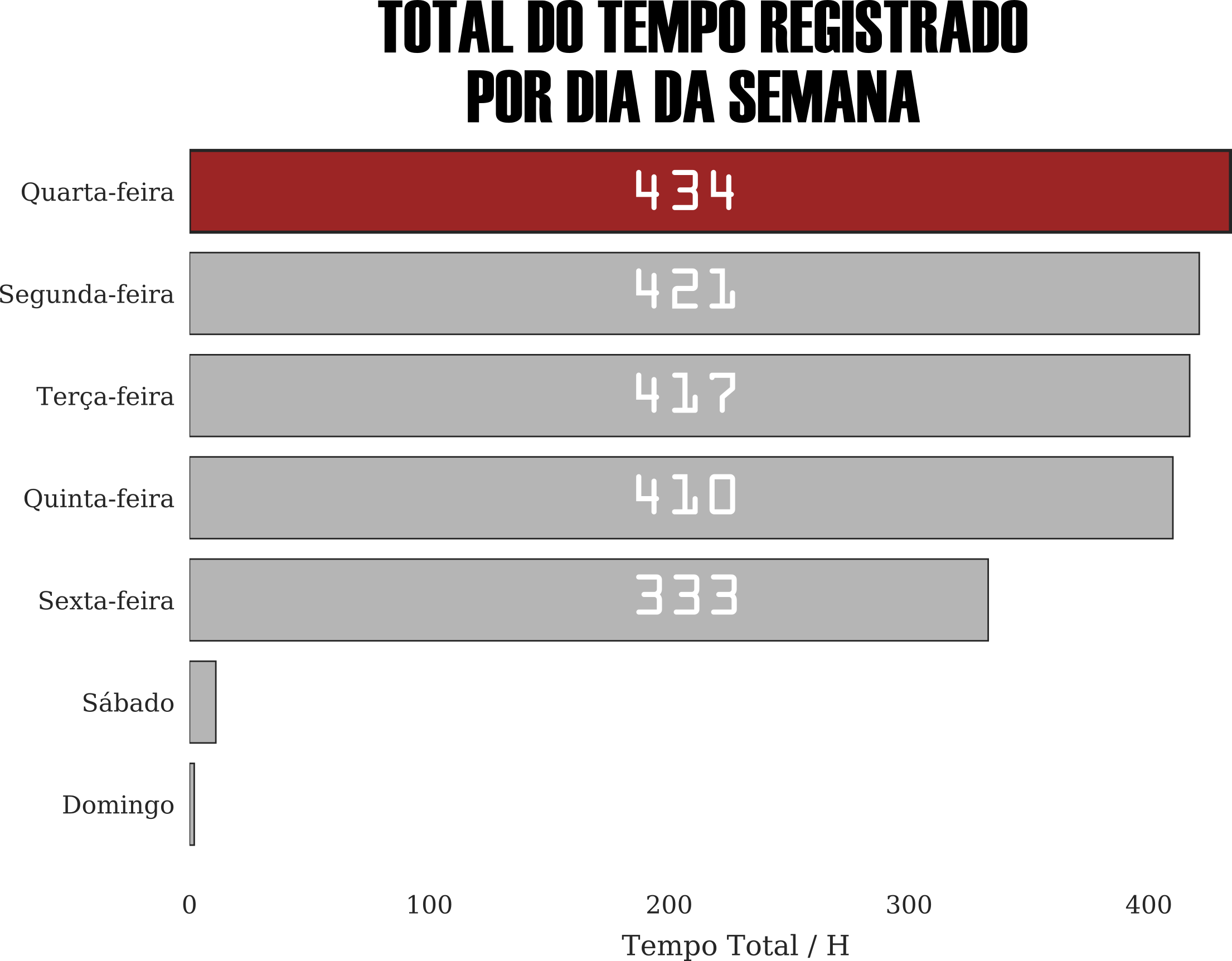
Já apresentamos evidências da consolidação de um novo hábito e que ele ocorre, prioritariamente, nos dia de semana. Mas ainda não falamos sobre o que eu decidi monitorar. A minha adesão ao lifelogging foi motivada, inicialmente, para organização do meu cotidiano para que fosse possível organizar meus estudos em data science, mas rapidamente foi extendida para um monitoramento das minhas atividades profissionais e aos poucos também incorporei o registro do tempo dedicado a atividade física, por exemplo. O gráfico abaixo, consolida esses dados.
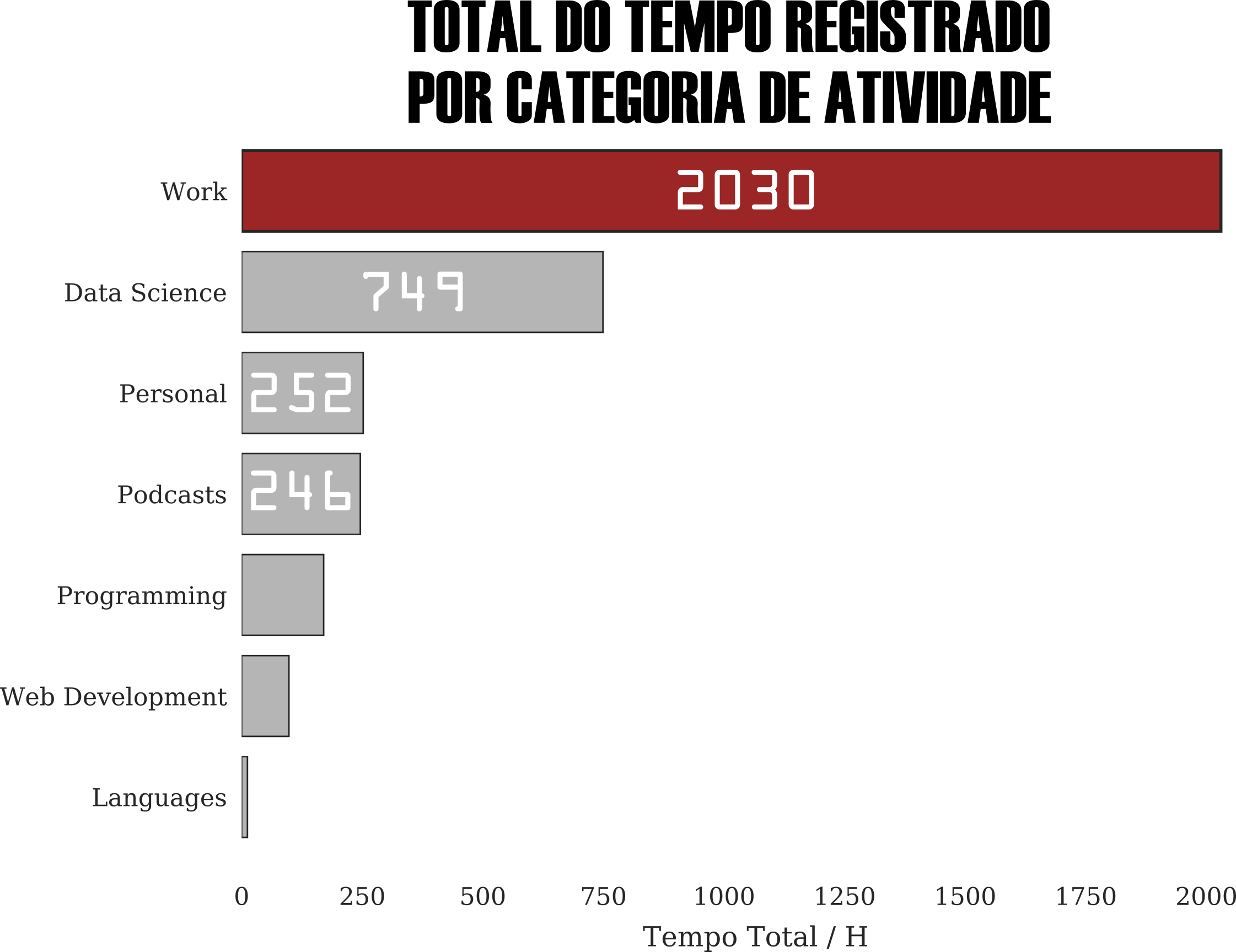
A imagem revela que a maior parte do meu tempo registrado está ligada as minhas atividades profissionais, como tenho uma jornada de trabalho em tempo integral é razoável imaginar que ela ocuparia a maior parte do meu tempo de registro. Além da consolidação do tempo total, é possível explorar algumas características a respeito da minha produtividade ao longo de um dia de trabalho.
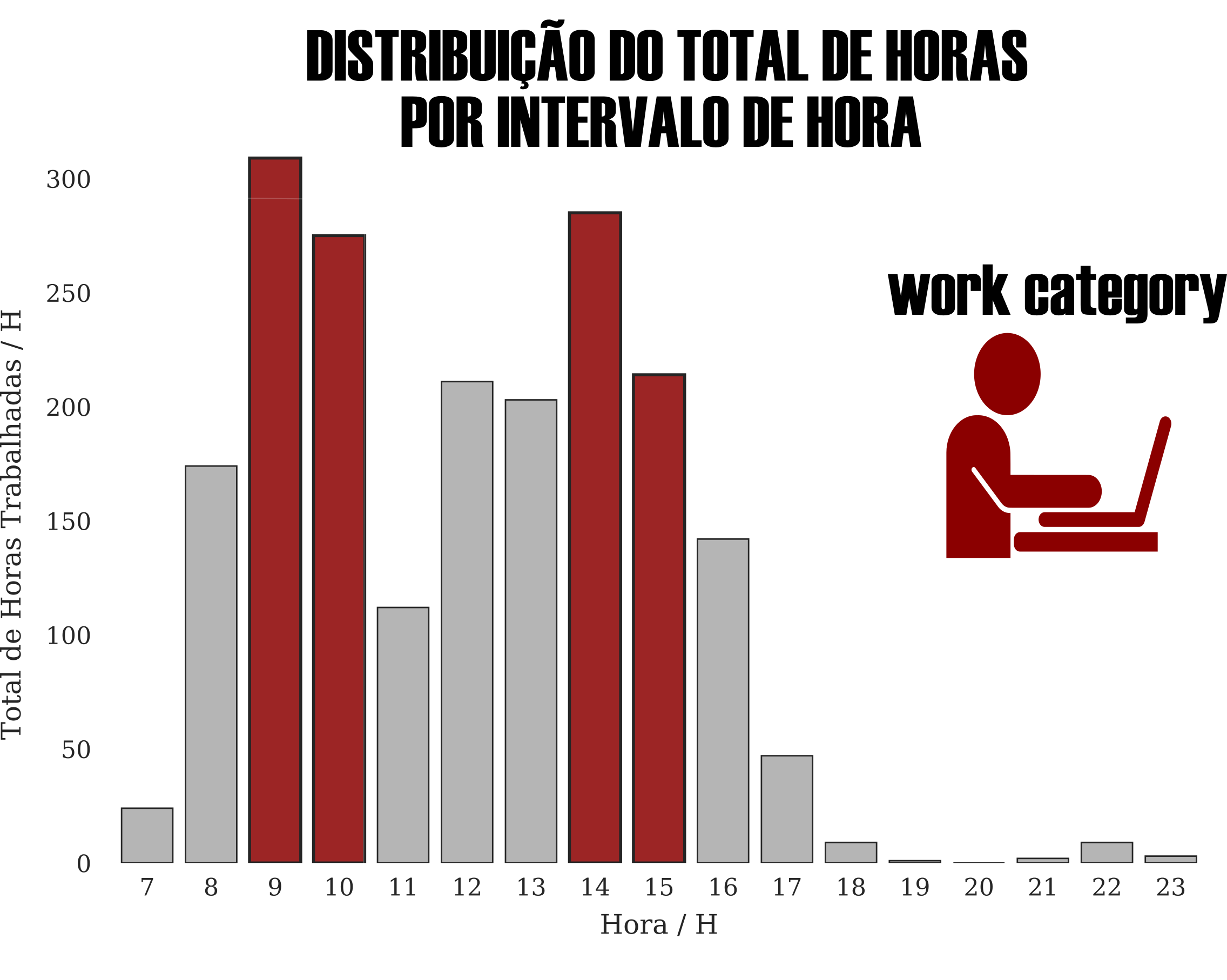
A construção de uma distribuição do total de horas trabalhadas ao longo de diferentes horas do dia revelou um histograma com dois picos: um no horário matutino entre as 09h:00min e 10h:59min da manhã e outro no vespertino entre as 14h:00min e 15h:59min. Além disso, os dados parecem se organizar em torno de algo próximo a uma distribuição bimodal.
Os dados me proporcionam a clareza necessária para saber em quais momentos ao longo do dia sou mais produtivo, portanto, aquelas reuniões clássicas que poderiam ser resolvidas em um email, eu tenho a condição de negociar para horários que não sou tão produtivo.
Abordado alguns padrões relacionados a minha rotina de trabalho, podemos explorar alguns aspectos da minha trajetória de incorporação de conhecimentos ligados a área de data science. Essa é uma área que tem despertado muito interesse nos últimos anos, e ao meu ver, a maior característica dela é a sua intrínseca interdisciplinaridade, e nada mais icônico para demonstrar isso que o diagrama de venn que mostra a intersecção entre conhecimentos das áreas de matemática/estatística & computação & área de negócio. Compartilho com vocês, uma citação muito famosa que considero adequada para representar esse profissional:
Um cientista de dados sabe mais de estatística que um cientista da computação e mais programação que um estatístico.
Desse modo, para organizar minha trajetória de aprendizado, comecei a registrar os meus estudos teóricos e projetos práticos nas áreas de ciência de dados, programação e desenvolvimento web. Além disso, em meados de 2017 eu descobri o incrível mundo dos podcasts e encontrei nessa mídia uma janela de oportunidade para adquirir conhecimentos ligados a área de ciência de dados, tecnologia, além de incorporar ao cotidiano maior exposição ao inglês (voltaremos a esse ponto, mais a frente).
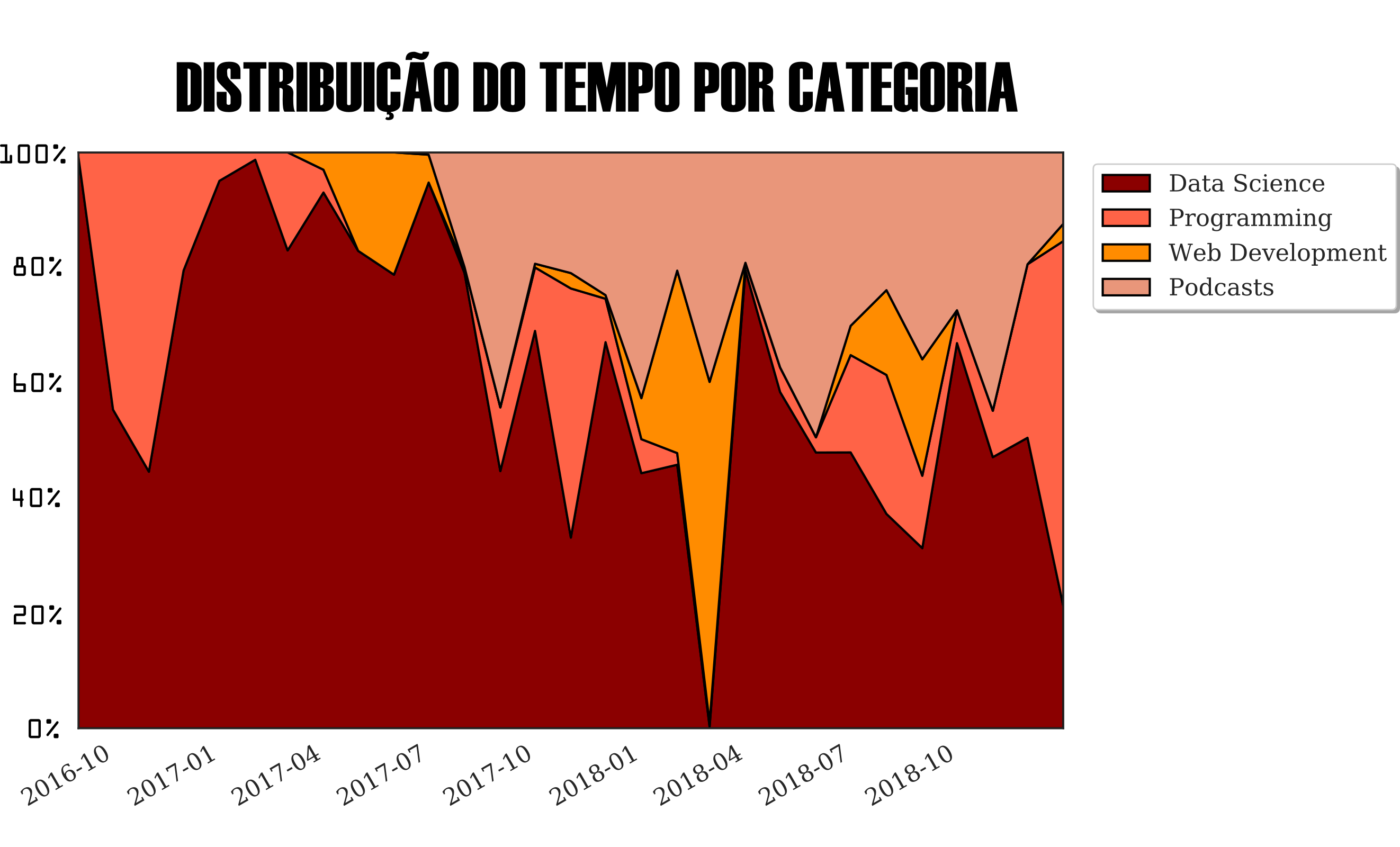
O gráfico de área empilhada mostra as três categorias de aprendizado prioritárias, além disso, eu selecionei o tempo investido em podcasts ligados a área de ciência de dados ou de tecnologia da informação. No início da minha trajetória de lifelogging foi evidente o tempo investido em me aprofundar em assuntos ligados a área de data science e quanto mais eu aprendia, mas era perceptível que era necessário investir tempo em outras frentes, principalmente as ligadas a programação, tais como design pattern, testes, integração contínua, banco de dados, versionamento de código, entre outras (a lista é longa!).
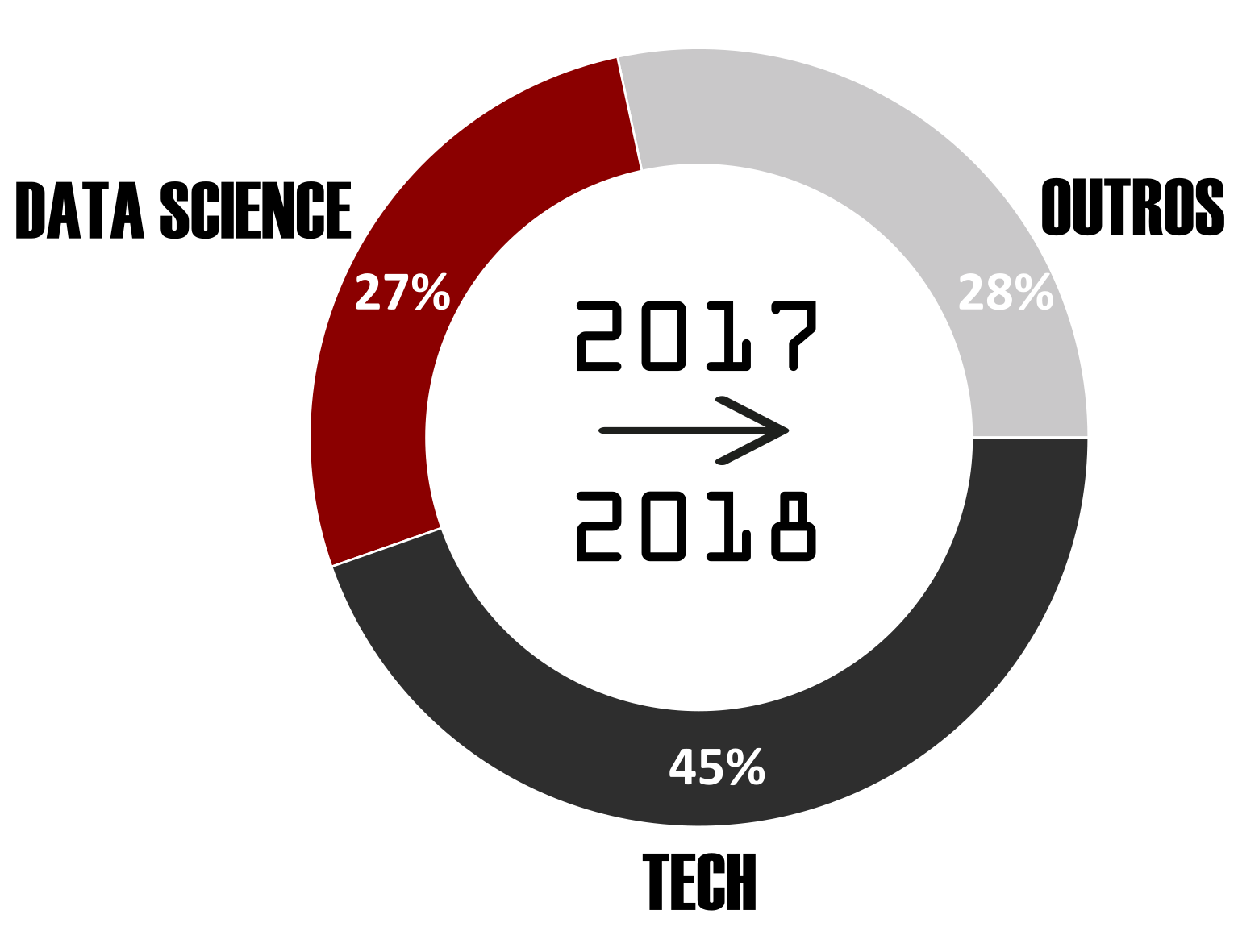
O gráfico de pizza abaixo mostra que mais de 70% do tempo que fiz uso desse recurso foi para assuntos ligados a ciência de dados e tecnologia, os dados mostram que falta diversidade de conteúdo, certo? Mas é proposital devido ao ambiente de imersão que criei para acelerar meu aprendizado numa nova área do conhecimento.
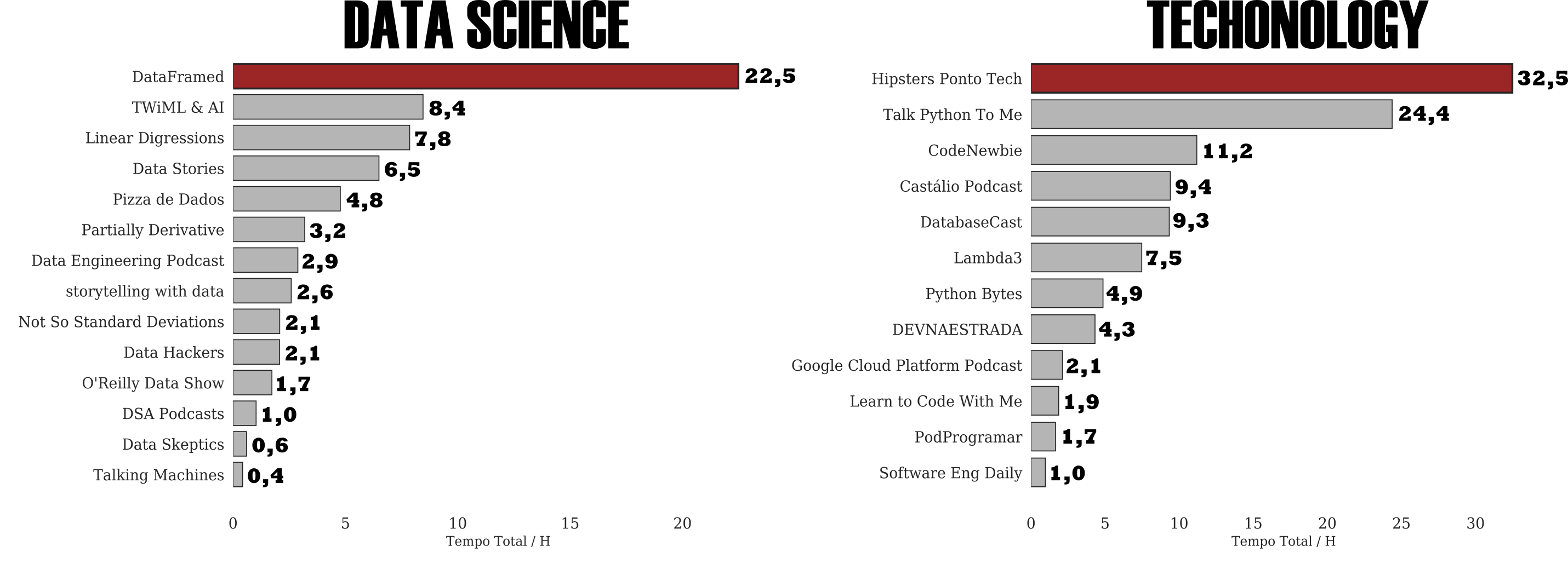
Gostaria de destacar a importância que credito aos podcasts nessa experiência de aprendizado profissional e pessoal, caso você ainda não conheça, não perca tempo e incorpore na sua rotina. Dito isso, apresento a listagem dos programas mais populares na minha playlist divididos por assunto.
Por último, e não menos importante, para qualquer pessoa que pretenda ingressar na área de data science ou mesmo de tecnologia é imprescindível o conhecimento de inglês.
Você precisa criar o ambiente necessário em sua vida para a concretização dos seus sonhos, portanto, os podcasts podem ser mais uma maneira de incorporar o contato com um idioma estrangeiro no seu dia a dia.
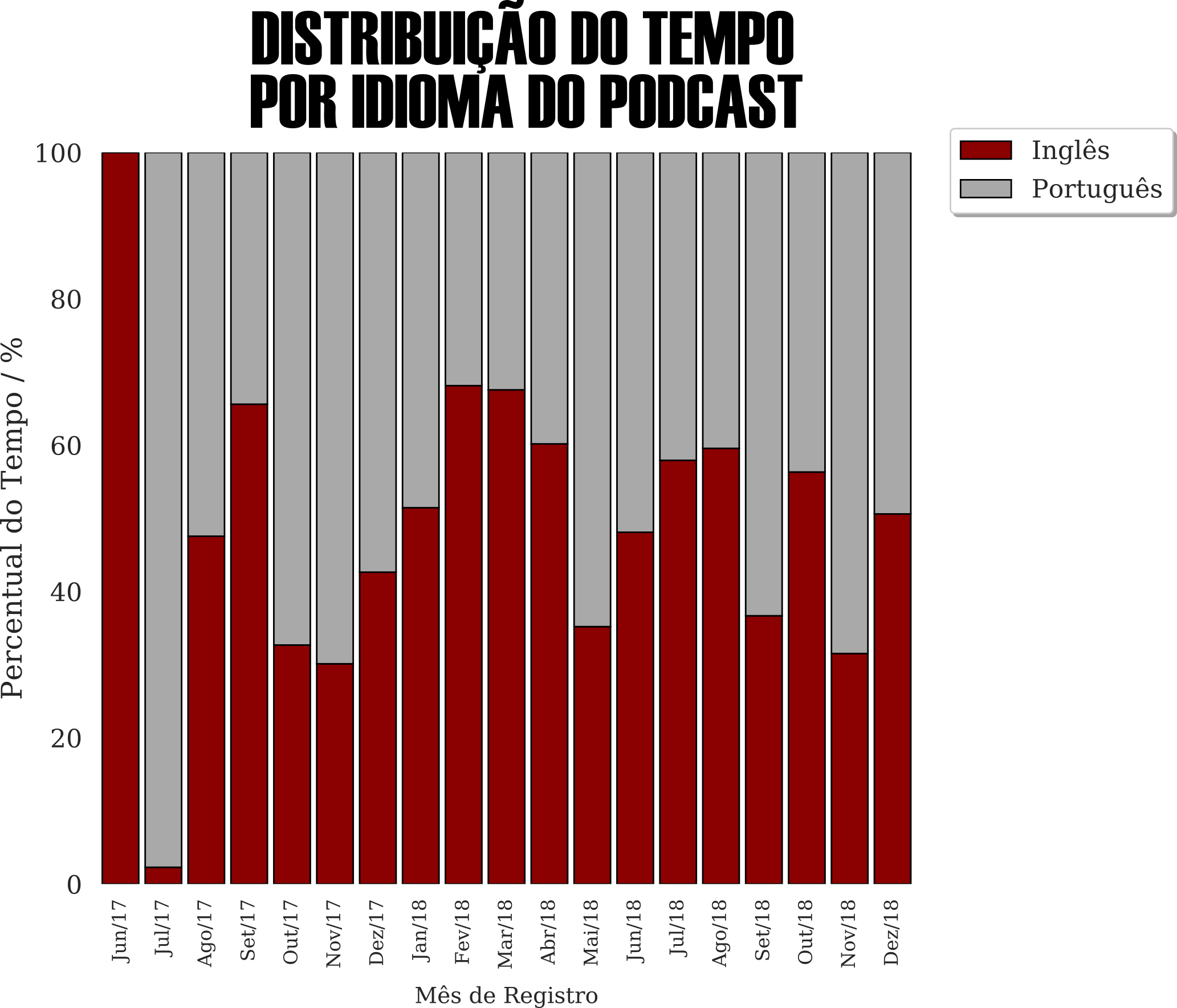
O gráfico de barras empilhadas mostra que, a exceção de Julho de 2017, os podcasts em inglês sempre estão presentes de forma significativa na minha rotina, colaborando no mínimo, em duas frentes: o assunto técnico e o idioma estrangeiro.
Assim, acredito que abordei diversos aspectos ligados a construção de uma vida data-driven. Além disso, você já experimentou alguma experiência de lifelogging ou tem algum comentário sobre a minha experiência? Deixe o seu comentário e até a próxima postagem!